Data movement for Google services at Netflix
By Raghuram Onti Srinivasan and Tianlong Chen
Netflix Studio is creating many hundreds of titles per year and a lot of this information is in varied data sources. We in the Data Platform organization have partners at Netflix Studio using services like Google Sheets and Google Drive for day to day operations. At the same time, we have the need to have this information in our Data warehouse for Data scientists to analyze the data. This has resulted in upwards of 20,000,000 files in Google Drive in varying formats (Sheets, Drive blobs, Docs and Slides).
With this proliferation of use cases requiring programmatic access to different Google services there were two major issues which needed to be tackled.
- Application owners and data scientists were managing security credentials and reusing code to authenticate with Google. They would otherwise have to set up separate GCP cloud projects to authenticate their projects. This made the bar higher for transferring data between Google services and our data warehouse.
- There was also a huge observability gap about what data was moving from the Data warehouse to Google and vice versa.
Here we will look into how we solve these two problems by having a service which serves as a proxy for all of Google services when accessed programmatically. By having an intermediary service between internal applications and Google APIs we can effectively solve for authentication in the proxy service and also log required information about the data which is being moved into a log for analysis and history (more on this later).
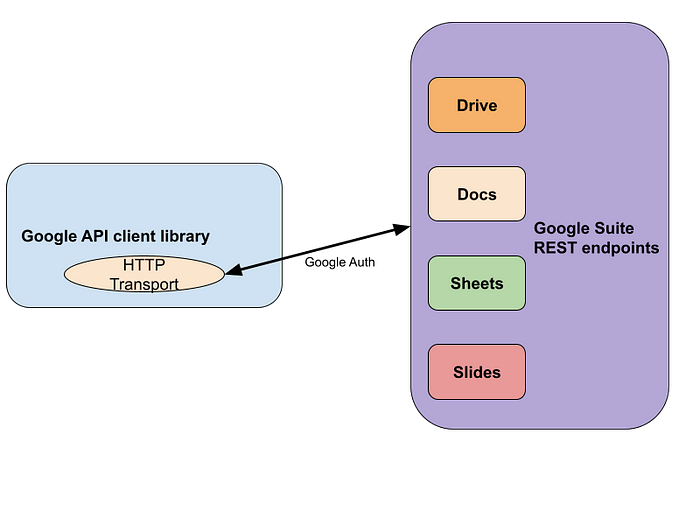
Google suite client architecture
Google’s suite of services discussed here include Docs, Slides, Drive and Sheets. Google provides REST APIs for each of these services and SDKs for different languages which have APIs to easily convert user intent into the corresponding REST calls.
At Netflix, developers in the Studio and Product organizations tend to use these SDKs to write one off scripts in Python or entire applications in Java which talk to Google services. The services are accessed mainly to move data between our internal data warehouse solution and Google services.
This also means we have multiple code bases where a very important aspect of code is repeated; securely connecting to the Google suite. We would also have to build audit mechanisms into these systems and repeat it with every new workflow where data moves between these services. We solved both of these problems by having a service which acts as a proxy to all Google services when accessed programmatically from applications.
Google proxy
Let us see how we can add a layer between Google services and applications accessing these services. We wanted to be able to touch a minimal amount of client code and have users be completely abstracted away from the fact that they are actually not talking to Google directly. We have a Spring boot application in Java which depends on the Google API client jar. This application acts as a proxy for all of Google services which need to be accessed from within Netflix. Google API clients rely on HTTP headers and body information being populated correctly in the request. We make use of service accounts provided by Google Cloud in order to securely talk to Google. Google Cloud provides a way to link an email address to a service account. The workflow to on board a user is as follows -
- The user shares the concerned document with the email address associated with a service account.
- The application running inside the Netflix ecosystem has credentials managed by an internal tool called Metatron. This tool also manages credentials on the proxy.
- When the client makes a request to modify (or read) a resource on Google the proxy receives the request, verifies the credentials and makes the request to Google on behalf of the client. Results of the request are then returned back to the client.
This service is also implemented with the Spring Boot reactive framework since the maximum amount of work to be done is mainly IO oriented.
Client
The Google SDK works by providing hooks which convert user intent to HTTP calls for the REST endpoints provided by Google. This way different languages can just work on translating the intent to HTTP calls and the server would always have a single way of handling clients irrespective of the language that was used.
Let’s take a closer look at how this works. We use gRPC to define the endpoint which is used to receive requests from the clients. This way we can generate clients in all the languages supported by gRPC. We only wrap the corresponding client side packages with the HTTP transport inserted so that the clients talk to the proxy via Metatron authentication instead of directly hitting Google endpoints using Google authentication.
Python/Java/gRPC supported language
The library relies on a generic HTTP interface to be able to talk to Google services. This has the advantage of inserting the proxy endpoint followed with any other information that the client wishes to convey to the proxy directly.
Data movement job
We wanted to make data transfer between our data warehouse and external Google services very easy for anybody within Netflix to use. So, we built this into our data portal where people can access tables in Iceberg using queries from Presto or Spark. When people query data from tables we provide an easy way to set up a job which can be scheduled to run at a specified cadence so that they can keep the data in the table refreshed in a particular Google Sheet.
Lineage
This system has been used extensively in our production environment. We currently have around 1 million transactions per week (and rising). In this system we’re moving data between organizations and would need to have visibility about the type of data and the direction of movement. We built this into the proxy so that we have an audit trail.
Clients accessing the proxy authenticate using our internal tool (Metatron) and provide information about the caller. We use this in the proxy service to log information about the transfer of data happening between Google and internal systems. For example, if a ETL (Extract Transform Load) job is reading a source table from our data warehouse and writing that information into a Google Sheet, we can log that information back into an audit table which will store all information about data movement happening within Netflix.
This data includes the following salient points -
- Source (could be the source table, Google Sheet etc)
- Destination (destination table, Google Sheet etc.)
- User / Application information (captured from the Metatron authentication context)
This way we can look up the lineage of a particular resource on Google (Sheet/Doc/Drive object) and see which table is the source for that information and vice versa. The lineage information is generated in the schema defined by the Iceberg table for capturing all audit information across various systems at Netflix. The Proxy service will produce events which match this schema.
Production
We’ve been running our proxy in production for more than one and a half years with more than 500 scheduled jobs which move data. Along with this, we have services using the proxy in real time to get or post information from Google services. We’re managing more than 20,000,000 objects with this system and this is growing as more titles are handled by our studio organization.
Stay Tuned
We’re looking to build more into the architecture discussed here. For example, the current system does not provide a way for applications to restrict access to the objects at an application level and we’re looking into what would be the best way to add that capability. Please post your comments below and stay tuned for updates on how we’re handling problems in the Data Platform organization within Netflix.
Acknowledgements
We would like to thank the following persons and teams for contributing to the Google Proxy service: Data Integrations Platform team (Andreas Andreakis, Yun Wang), Production Foundations Engineering (Sasha Joseph), Content Engineering (Ismael Gonzalez), Data Science and Engineering (Dao Mi, Girish Lingappa), Data Engineering Infrastructure(Ajoy Majumder), Information Security (Rob Cerda, Spencer Varney) and Jordan Carr.
