Improving Pull Request Confidence for the Netflix TV App
By: Nadeem Ahmad, Ramya Somaskandan
Introduction
The Netflix TV app is used across millions of smart TVs, streaming media players, gaming consoles, and set-top boxes worldwide. As the team that focuses on developer productivity for the org, our role is to enable the engineers that develop, innovate on, and test this app to be more productive.
In practice, one of the ways we do this is by providing data as to whether a code change is safe to merge to the main branch or not. There are a few reasons that it is crucial for us to get this right. First of all, the Netflix TV app codebase is very nuanced, and goes through a lot of updates. To provide an idea of scale, there are roughly:
- 50 different engineers that contribute to the codebase regularly
- 250 changes on average that get merged each month to the codebase; this year our busiest month had 367 merged changes (see chart below for a month-by-month breakdown over the first half of this year)
Additionally, the scope of these changes is broad due to both the size of the codebase and the number of engineers working on it. This means that rigorous testing is essential, and thus we have a sizable number of tests in our test suite. In fact, we run nearly a thousand functional tests across a variety of devices and versions, resulting in several thousand test runs; all these tests are run every time a pull request is created, updated, or merged. This means that we have an enormous amount of tests that are executed each day. If a test fails for any reason (failures are obviously more common in functional tests than the tests in the lower rungs of the testing pyramid), we have to retry multiple times to counteract flakiness.
Therefore, the functional tests are run asynchronously and the results are shown to the user as they become available (rather than all at once). The diagram below is a cursory look at the development workflow for a TV engineer at Netflix.
- The developer iterates on their change on a development branch
- Once the change is ready for peer review, they create a pull request
- This kicks off the CI process and test results start coming in as they finish running
- When the entire test suite has finished running, the developer is responsible for analyzing the results and determining whether the change is safe to merge or not
- If the developer judges the change to be safe, they merge the pull request to the main branch
This manual judgement process is required because of the flaky nature of the end-to-end functional tests. One way we are addressing this flakiness directly is by continually improving the quality of the tests that we write. We have another tool known as the test stability pipeline, which ensures that only sufficiently stable tests make it to the official test suite. Even then, having flaky functional tests on devices is practically unavoidable. The goal is, therefore, to minimize the number of flaky tests and to provide developers as much insight as possible to determine whether a functional test failure is caused by their change or not.
Providing Test Confidence Data
Even though we are acknowledging that it may not be feasible to provide 100% confidence that a test failure is not due to a developer’s change, we can still provide an indication towards that: any signal that can guide the developer towards making an informed decision is remarkably valuable. Therefore, our goal is to indicate whether a failing functional test is “likely” or “unlikely” due to the developer’s commit and to provide this information to the developer as part of the CI process.
How do we do this?
Primarily, we need some way of determining how an existing test performs with and without the developer’s code change. Out of these two, we already know how a test performs with the code change. We just ran it as part of CI! Now, how do we know how a test performs without the code change? Well, we need to look at how the same test runs on the destination branch.
Naturally, the entire test suite is run whenever a pull request is merged to the main branch. So, for our first stab at this, we leveraged this fact: we are already sitting on all this useful trove of data, so why not also apply that data for this use case?
That’s precisely what we did for our initial version.
How did it work?
Roughly, this is how this version of providing test confidence data to developers worked:
- If a test fails in CI, even after the appropriate number of retries, we look up the results for different runs of that test on the main branch over the last 3 hours.
- Based on how often the test failed in the main branch, we assign a “score”. If the score reaches a certain (tunable) threshold, we indicate that the failure is “unlikely” due to the developer’s change.
- For example, a functional test that is failing consistently on the main branch would have a score closer to 100. In that case, the test would be safely above the set threshold and it would be shown to the user that this particular failure is unlikely due to their change.
This “confidence score” number is also available as a reference for developers as part of the metadata associated with the test run.
Now what happens if there are no test runs on the main branch for the last X number of hours, because no commit has been merged to main for that period of time? To address this, we scheduled a Jenkins job to run the full suite of tests every two hours and gather data that can be used for computing confidence scores. The test runs from this job were set at a lower priority than the regular test runs so that this job would not hog resources and interfere with the main CI process.
Alright great, so we are done right?
Well… not quite.
Improving the Initial Version
Staying true to the Netflix culture and values, we received and gathered feedback to see how the tool was working in practice.
From that feedback, there were three main areas for improvement that were identified:
- First, there might be no test data available for the main branch in the 3 hour time window. As mentioned earlier, the tests that were run via the Jenkins job were given lower priority on the devices. So, all tests may not have run every 2 hours on the main branch.
- The other and more important issue was that even if fresh test data were available within the last 2–3 hours, the data were still often too stale to compute a reasonable confidence score with. Major causes of test flakiness include dependencies going down or devices behaving unexpectedly, and that can happen at any point in time. Therefore, test results from a few hours ago only yield limited value.
- Finally, developers wanted to move away from the idea of a confidence “score” and instead preferred being shown some sort of “report”. We realized that providing a score, and an indication of “likely” vs. “unlikely” based on that score, was hiding some of the information that we had available from our users.
Therefore, we set out to address these gaps, by working on an updated version to provide better test confidence data to developers.
How did we address these gaps?
As it was noted earlier, for failing tests, we make at least 4 attempts to see if the test failure is consistent. Thus, instead of using all these attempts for running the test against the pull request, why not use one of the retry attempts to run the test against the destination branch? In other words, if a test fails 3 times, why not use the 4th attempt to run directly against the destination branch and store the results? This would provide directly applicable data that can be used to assess confidence to a much higher degree of accuracy than was done in the initial version.
Additionally, in this version, if a test fails on both the pull request run and on the destination branch run, we can compare the error output and provide that information to the developers.
The flowchart below shows how this version works.
Developers are able to see the new and improved confidence “report” alongside their test results in CI. The screenshots below is what a developer would see when trying to analyze functional test failures on their pull request. The confidence indicator (the exclamation mark icon) is directly on the banner for failed tests. If the user hovers over the confidence indicator, they are shown details as to which of the three scenarios occurred for that particular test.
Note that in the first scenario we mark the test a shade of orange instead of red. This provides users a visual cue that this test failure is unlikely due to their change.
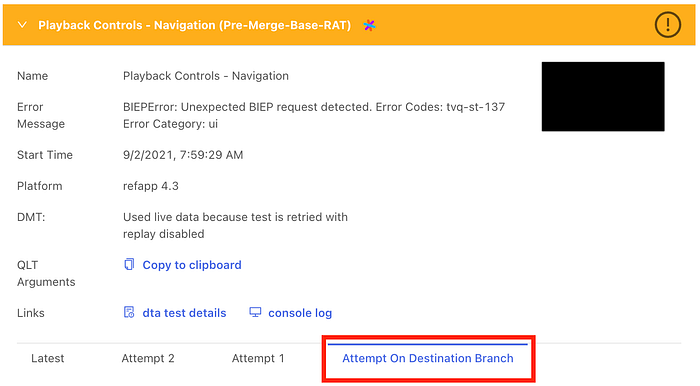
Another cool feature with this version is that users are able to see the full details of the test run on the destination branch, just as they would for the pull request runs (see screenshot below). Having the test results for the destination branch run side-by-side with the test results for the pull request runs is especially useful for developers and test engineers.
Finally, to ensure we always provide users with some information as opposed to none, in cases where we are unable to run the test on the main branch for any reason, we fall back to the initial version of confidence scores.
Benefits of the Improved Version
With the release of the new version, we saw marked improvement in the availability of confidence data. Let’s look at a quick example that illustrates how the updated version provides value where the previous version did not.
For each functional test run, we store the associated metadata in MongoDB. As part of this metadata, we capture what the initial version of the confidence score would return, so that it can be used as a fallback. The screenshot below shows the subset of the captured metadata for an example test run. The blue box specifically highlights the JSON object storing the initial confidence score data. We can see that the initial version would not have provided the user with any useful data. Then, if we look at the JSON object corresponding to the updated version (the red box), we can see that it found that the status and the error message was the same for both the pull request run and the destination branch run.
Therefore, the test failure is very unlikely to be due to the user’s change. This information would not be available to the user with the initial version.
Let’s take this a step further, and look at how much more useful data was provided to developers since the “new” confidence data was fully rolled out. We looked at some 130K relevant failed tests over the last 3 months and found that significantly more failed tests had the new confidence data attached compared to the old confidence score. The chart below displays that data in percentage form.
74% of the relevant failed tests have at least some version of confidence data compared to only 35% if we had stayed with the original confidence score. Additionally, we observe a significant 21% increase in the number of tests that now have confidence data but didn’t before. Of course the new confidence data is also more relevant and more precise than the previous version.
What’s Next?
Here are a couple of ways we are thinking about improving confidence in test results for the future:
- We can match the number of test runs on the main branch with the number of test runs on the pull request. Currently, we generally end up having 3 test runs for the pull request, while only having a single attempt on the main branch. We can increase the number of attempts on the main branch to ensure the error output is consistent across multiple retries. Obviously, there is a trade-off here as this will require additional device resources.
- We can use additional historical test run data along with test run data from concurrent pull requests, to provide users even more information to ascertain whether a test failure is due to their change or not.
- We can leverage the vast amount of new confidence data that we are gathering as a result of this project to readily identify particularly unstable tests and closely analyze the root cause of their instability. This will allow us to tackle the problem of test flakiness head-on and address the larger issue of test stability directly.
Overall, our goal is of course to deliver clear signals and pertinent information to developers so that they can make well informed decisions, and we are only just getting started.