Lessons Learnt From Consolidating ML Models in a Large Scale Recommendation System
by Roger Menezes, Rahul Jha, Gary Yeh, and Sudarshan Lamkhede
In this blog post, we share system design lessons from consolidating several related machine learning models for large-scale search and recommendation systems at Netflix into a single unified model. Given different recommendation use cases, many recommendation systems treat each use-case as a separate machine-learning task and train a bespoke ML model for each task. In contrast, our approach generates recommendations for multiple use cases from a single, multi-task machine learning model. This not only improves the model performance but also simplifies the system architecture, thus improving maintainability. Additionally, building a common extensible framework for search and recommendations has allowed us to build systems for new use-cases faster. We describe the trade-offs we made for achieving this consolidation and lessons we learnt that can be applied generally.
Background
In large real world recommender system applications like e-commerce, streaming services, and social media, multiple machine learning models are trained to optimize item recommendations for different parts of the system. There are separate models for different use-cases like notifications (user-to-item recommendations), related items (item-to-item based recommendations), search (query-to-item recommendations), and category exploration (category-to-item recommendations) (Figure 1). However, this can rapidly result in systems management overhead and hidden technical debt in maintaining a large number of specialized models (Sculley et al., 2015). This complexity can lead to increased long-term costs, and reduce the reliability and effectiveness of ML systems (Ehsan & Basillico, 2022).
Figure 2 shows how such an ML system with model proliferation might look. The different use-cases like notifications, related items, search and category exploration have different UI canvases where the user interacts with them. ML systems for these different use-cases often evolve to have multiple offline pipelines that have similar steps such as label generation, featurization and model training. On the online side, different models might be hosted in different services with different inference APIs. However, there are a number of commonalities in both offline pipelines and online infrastructure, which such a design does not leverage.
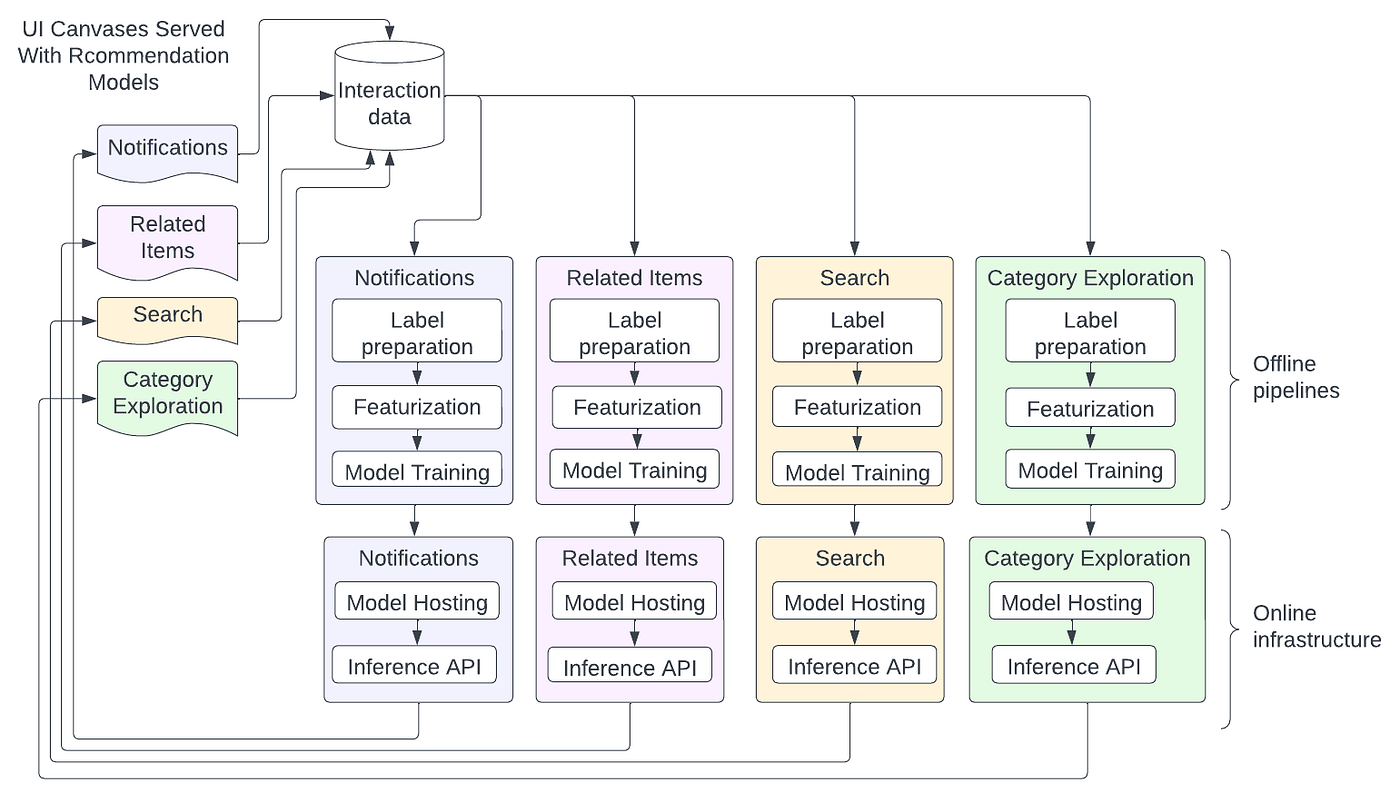
In this blog, we describe our efforts to leverage the commonalities across these tasks to consolidate the offline and online stacks for these models. This methodology not only reduces technical debt but also enhances the effectiveness of the models by leveraging knowledge gained from one task to improve another related task. Additionally, we noticed advantages in terms of efficiently implementing innovative updates across multiple recommendation tasks.
Figure 3 shows the consolidated system design. After an initial step of use-case-specific label preparation, we unify the rest of the offline pipeline and train a single multi-task model. On the online side, a flexible inference pipeline hosts models in different environments based on the latency, data freshness and other requirements, and the model is exposed via a unified canvas-agnostic API.
Offline Design
In an offline model training pipeline, each recommendation task maps to a request context where recommendations need to be shown. The request context schema varies depending on the specific task. For instance, for query-to-item recommendation, the request context would consist of elements like the query, country, and language. On the other hand, for item-to-item recommendation, the request context would also include the source item and country information. The composition of the request context schema is tailored to suit the requirements of each recommendation task.
An offline pipeline trains models from logged interaction data in these stages:
Label preparation: Clean logged interaction data and generate (request_context, label) pairs.
Feature Extraction: Generate feature vectors for the above generated (request_context, label) tuples.
Model Training: Train a model based on (feature_vector, label) rows.
Model Evaluation: Assess the performance of the trained model using appropriate evaluation metrics.
Deployment: Make the model available for online serving.
For model consolidation, we set the unified request context to the union of all context elements across tasks. For specific tasks, missing or unnecessary context values are substituted by sentinel (default) values. We introduce a task_type categorical variable as part of the unified request context to inform the model of target recommendation task.
In label preparation, data from each canvas are cleaned, analyzed and stored with the unified request context schema. This label data from different canvases is then merged together with appropriate stratification to get a unified labeled data set. In feature extraction, not all features contain values for certain tasks and are filled with appropriate default values.
Online Design
Serving a single ML model at-scale presents certain unique online MLOps challenges (Kreuzberger et al., 2022). Each use-case may have different requirements with respect to:
- Latency and throughput: Different service-level agreements (SLAs) to guarantee a latency and throughput target to deliver an optimal end-user experience.
- Availability: Different guarantees of model serving uptime, without resorting to fallbacks.
- Candidate Sets: Different types of items (e.g. videos, games, people, etc) that may be further curated by use-case-specific business requirements.
- Budget: Different budget targets for model inferencing costs.
- Business Logic: Different pre- and post- processing logic.
Historically, use-case-specific models are tuned to satisfy the unique requirements. The core online MLOps challenge is to support a wide variety of use-cases without regressing towards the lowest-common denominator in terms of model performance.
We approached this challenge by:
- Deploying the same model in different system environments per use-case. Each environment has “knobs” to tune the characteristics of the model inference, including model latency, model data freshness and caching policies and, model execution parallelism.
- Exposing a generic, use-case-agnostic API for consuming systems. To enable this flexibility, the API enables heterogeneous context input (User, Video, Genre, etc.), heterogeneous candidate selection (User, Video, Genre, etc.), timeout configuration, and fallback configuration.
Lessons Learnt
Consolidating ML models into a single model can be thought of as a form of software refactoring (Cinnéide et al., 2016). Similar to software refactoring, where related code modules are restructured and consolidated to eliminate redundancy and improve maintainability, model consolidation can be thought of as combining different prediction tasks into a single model, and leveraging shared knowledge and representations. There are several benefits to this.
Reduced code and deployment footprint
Supporting a new ML model requires significant investment in code, data and computational resources. There is complexity involved in setting up training pipelines to generate labels, features, train the model and manage deployments. Maintaining such pipelines requires constant upgrades to underlying software frameworks and rolling out bug fixes. Model consolidation acts as an essential leverage in reducing such costs.
Improved Maintainability
Production systems must have high availability: any problems must be detected and resolved quickly. ML Teams often have on-call rotations to ensure continuity of operation. A single unified code base makes the on-call work easier. The benefits include little to no context switching for the on-call, homogeneity of workflows, fewer points of failures, and fewer lines of code.
Apply Model Advancements Quickly to Multiple Canvases
Building a consolidated ML system with a multi-task model allows us to apply advancements in one use-case quickly to other use-cases. For example, if a certain feature is tried for a specific use-case, the common pipeline allows us to try it for other use-cases without additional pipeline work. There is the trade-off of potential regression for other use-cases as features are introduced for one use-case. However, in practice, this has not been a problem if the different use-cases in the consolidated model are sufficiently related.
Better Extensibility
Consolidating multiple use cases into a single model prompts a flexible design with extra thought in incorporating the multiple use cases. Such essential extensibility consequently future-proofs the system. For example, we initially designed the model training infrastructure to consolidate a few use cases. However, the flexible design necessitated to incorporate these multiple use cases has proved effective to onboard new model training use cases on the same infrastructure. In particular, our approach of including variable request context schemas has simplified the process of training models for new use-cases using the same infrastructure.
Final Thoughts
Though ML system consolidation is not a silver bullet and may not be appropriate in all cases, we believe there are many scenarios where such consolidation simplifies code, allows faster innovation and increases the maintainability of systems. Our experience shows that consolidating models that rank similar targets leads to many benefits, but it’s unclear whether models that rank completely different targets and have very different input features would benefit from such consolidation. In future work, we plan to establish more concrete guidelines for when ML model consolidation is most suitable. Finally, large foundation models for NLP and recommendations might have significant impact on ML system design and could lead to even more consolidation at systems level.
Acknowledgements
We thank Vito Ostuni, Moumita Bhattacharya, Justin Basilico, Weidong Zhang, and Xinran Waibel for their contributions to the ML system. Thanks also to Anne Cocos for her valuable feedback on a previous draft.
