Netflix Images Enhanced With AWS Lambda
by Mark Stier and Igor Okulist
At Netflix we believe in empowering content creation and enabling new product experiences. Specifically for us it means eliminating the technical roadblocks for our studio and business partners to get artwork content to Netflix users. To enable these teams we created Dynimo — Netflix’s dynamic image processing service.
While providing these needs we had to manage many challenges: content can go live at any moment, creative decisions can change the look and feel of our app which leads to new image assets or new image sizes (or both) and causes catalog wide changes and cache invalidation.
We were looking to enhance our infrastructure with AWS Lambda to tap into on demand scaling with low startup times and as a way to more efficiently handle additional traffic spikes.
The Demand Spike
Dynimo’s existing architecture is straightforward:
- User requests image from OCA (CDN)
- OCA forwards to Zuul if it does not have the image
- Zuul proxies request to Dynimo to generate image
- Dynimo returns image to Zuul
- Zuul returns image to OCA
- OCA caches the image and returns it to the user
Demand for images is generally serviced by OCA and origin only refreshes cache when it expires. New content and regional failures can happen at any moment. In these cases, traffic can easily spike 5–10x from its regular base level when this happens. OCA is the first line of defense against these traffic spikes. However without the data OCA must make requests to Dynimo for new content.

After OCA receives and caches the new images, it can then absorb the new content demand and Dynimo sees a dramatic drop in demand that disappears as fast as it arrives.
Without instances to service these image requests, OCA is left in limbo with no image to return with their request. This sharp demand places a burden on the Dynimo’s infrastructure to scale as OCA fills their cache. The challenge of scaling an on demand solution can be summed up in 2 parts:
- Metric Delays — When is there sufficient evidence that scaling is needed?
- Cold Start Time — How long until the new instances are able to take traffic?
In practice Metric Delays are 1 minute before a signal is triggered to start the scaling process. Cold Start Time can be minutes before an instance is available. The instance must startup the OS and the application then register its healthcheck with its ALB and with internal service Discovery before it can take traffic. This leads to Cold Start times lasting over a minute.

In practice we see the scaling complete minutes after the spike has occurred. Sometimes it misses the demand spike entirely.

A common solution that avoids these problems is to prescale a cluster large enough to provide a buffer for the demand. The buffer needed to provide Netflix with sufficient capacity requires thousands of instances to be running at all times. However this is an inefficient solution leading to an average resource usage below 10% and wasted money.
Lambda offers a platform where Demand and Supply(Active Instances) rise and lower together. It also only charges for what is used, making it cost effective.
Two Different Architectures
As part of the transition to Lambda we split Dynimo into 2 pieces. One piece, we called Dynimo Preprocessor, contained the business rules that would be used to generate an image on demand. The second piece, we called Dynimo Generator, did the downloading and processing of images. Generator would be the piece that ran on Lambda while Preprocessor would run on EC2.
While we explored Lambda, we quickly realized that there are clear differences between solution infrastructure deployed on Lambda compared to deployed on EC2.
For faster startup times, we rewrote the code base into golang. Originally Dynimo was written in Java. Java requires the JVM to startup leading to 500–800 ms of additional Cold Start time. To minimize this we used Golang which does not have a vm to startup and is compiled so no interpreter is needed.
We created a statically built binary of Imagemagick to match the version we used in EC2. For the background processing, we removed our background thread clean up and instead do foreground cleanup before returning the Lambda response. The background processing has the greatest impact on the coding style, unfortunately it prevents a seamless transition from one platform to another.
Results
We have been using Lambda for production since the beginning of 2020 and have been measuring its performance.
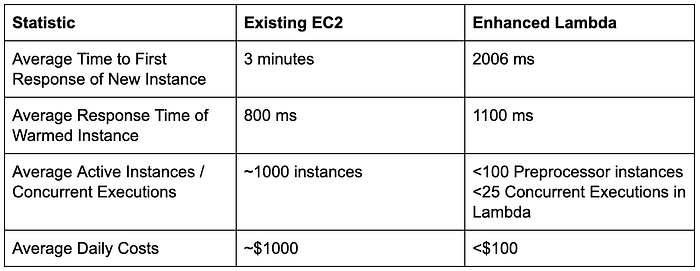
We have load tested Lambda to over 15x above normal traffic volume and have had Lambda in production experienced traffic above 20x regular volume. Our number of instances for Preprocessor has never been above 1/10th of what we had to run before. Overall the solution is showing an ability to massively scale without the need to have pre-scaled instances.
Looking Ahead
We are foreseeing having to work through some of the limits of Lambda.
- 50 MB max ZIP file size
- 5 MB max response size
- 512MB max /tmp directory size
- 2 CPU cores at most
- No Background processing
Many of these are size limitations that could be increased by AWS in the future or may require clever solutions. Our future goal is to build a more agnostic platform that will service more on demand applications. Lambda offers a unique ability to scale with demand and we are optimistic that these challenges will be solved.
References
Special Thanks To
Hunter Ford, Adam DePuit, Sujana Sooreddy, Jason Koch, Jonathan Bond
